ASR 供应商配置教程
本页汇总各 ASR 供应商的注册、开通与密钥获取方法,并说明如何在说点啥中完成对应配置。
开始前
- 进入应用
设置 → 语音识别设置,在「ASR 服务商」中选择目标供应商 - 云端供应商通常需要填写
API Key/Access Token等凭证 - 本地模型需先下载/导入模型文件(首次加载可能需要几秒)
安全提示
API Key / Access Token 属于敏感信息,请勿截图公开或分享给他人;如怀疑泄露,请立即在对应平台控制台删除并重新创建。
供应商一览
| 供应商 | 类型 | 流式支持 | 适合场景 |
|---|---|---|---|
| Volcengine 火山引擎 | 云端 | ✅ | 追求低延迟与流式实时出字 |
| SiliconFlow 硅基流动 | 云端 | ❌ | 新手开箱即用 / 低成本 |
| DashScope 阿里云百炼(Qwen) | 云端 | ✅ | 性价比与识别效果均衡 |
| Soniox | 云端 | ✅ | 海外服务、流式稳定性较好 |
| Gemini | 云端 | ❌ | 小用量体验 / 文件识别 |
| ElevenLabs | 云端 | ✅/❌ | 识别精度高,按模型区分流式 |
| OpenAI(兼容接口) | 云端 | ✅/❌ | 使用 OpenAI/兼容端点,支持文件识别与 Realtime 流式 |
| StepAudio | 云端 | ❌ | 阶跃星辰在线 ASR,支持中英文与 ITN |
| Zhipu 智谱 GLM | 云端 | ❌ | 低成本、简单接入 |
| OpenRouter | 云端 | ❌ | 使用 OpenRouter API Key 调用兼容 ASR 模型 |
| MiMo 小米 | 云端 | ❌ | MiMo v2.5 ASR / 音频理解模型 |
| Cohere | 云端 | ❌ | Cohere Transcribe 文件识别与多语言转写 |
| 本地模型(SenseVoice / FunASR Nano / Qwen3-ASR / Parakeet / FireRedASR V2 / X-ASR) | 本地 | 部分 ✅ | 隐私优先、离线可用 |
火山引擎(Volcengine)
火山引擎(豆包语音)中文识别能力较强,API 功能完善,支持流式与非流式。
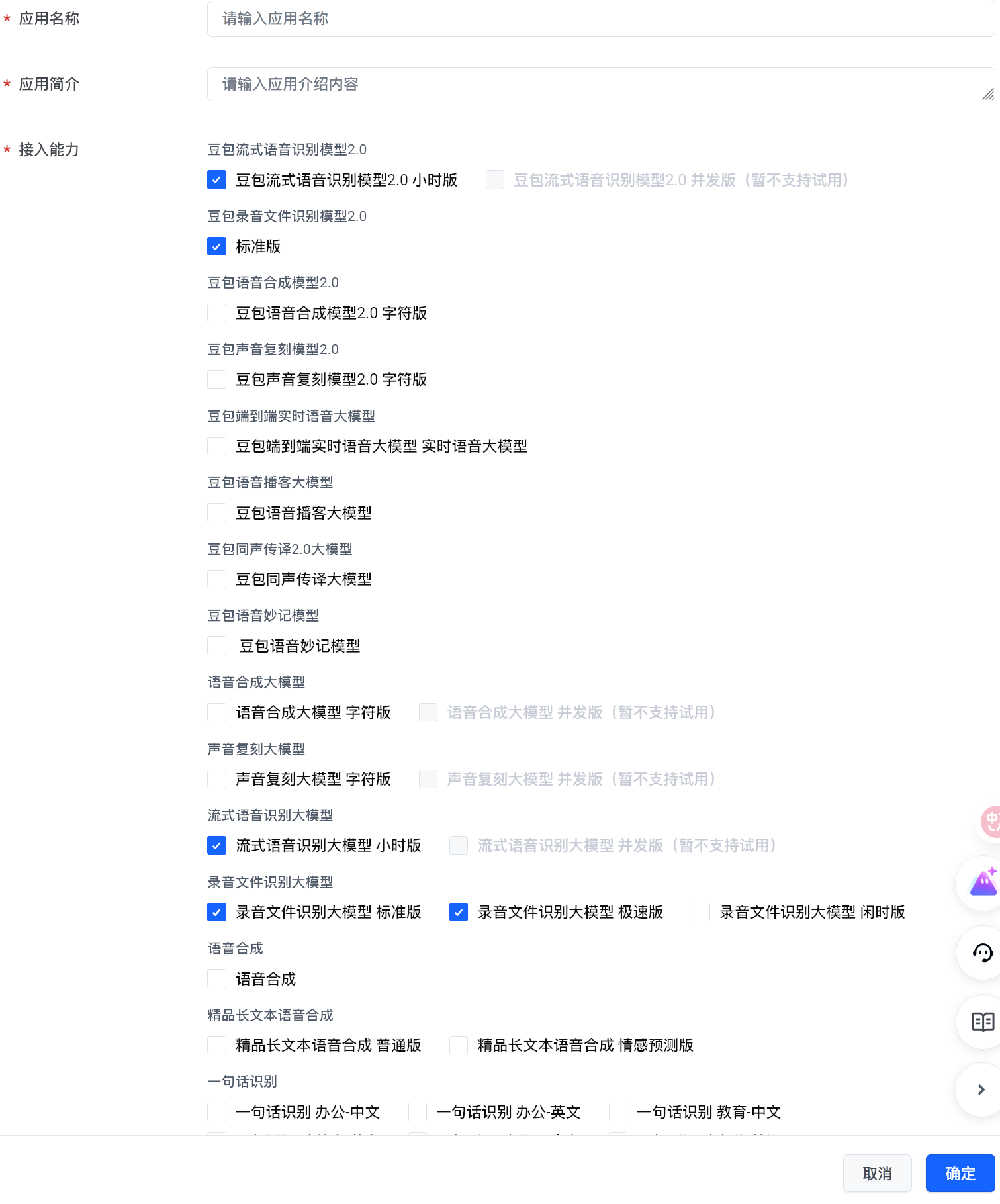
1. 创建应用并开通服务
- 进入控制台创建应用:火山引擎控制台
- 在「接入能力」中勾选:
流式语音识别大模型录音文件识别大模型极速版
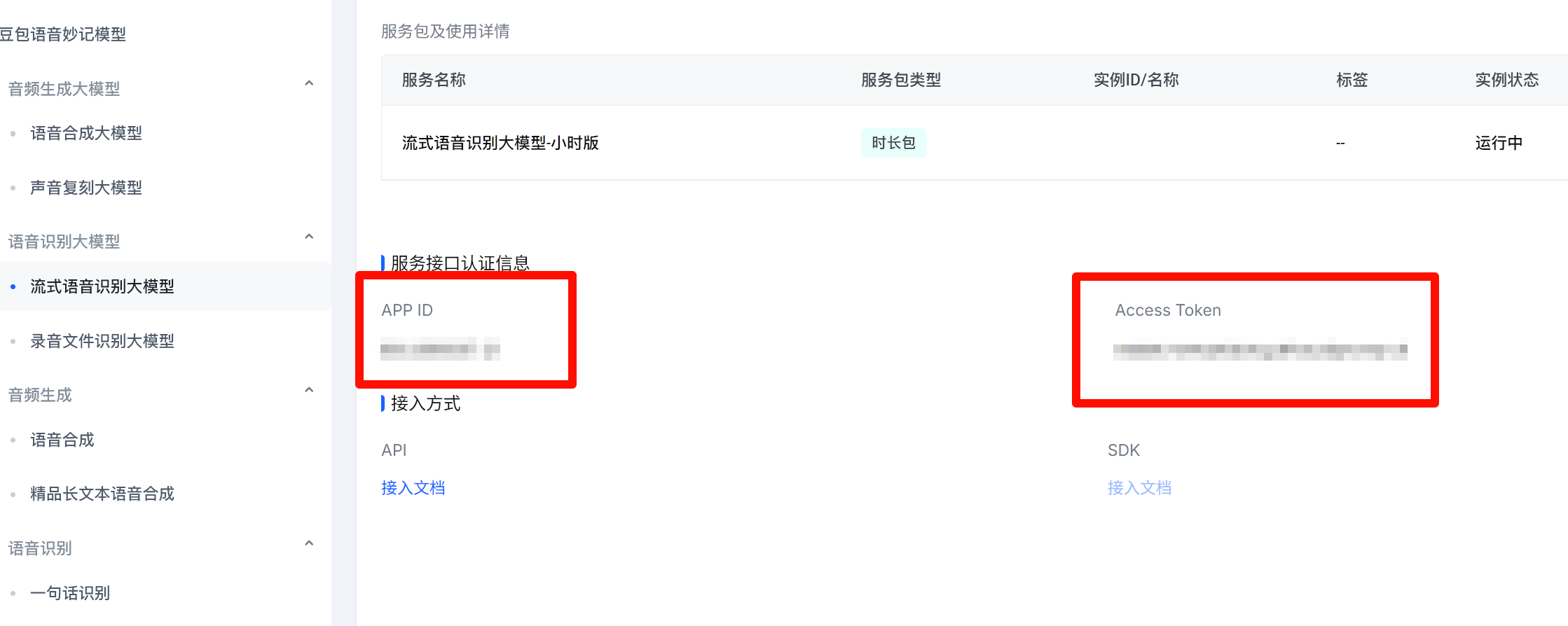
2. 获取 APP ID 与 Access Token
- 进入服务详情页:火山引擎语音服务
- 在「服务接口认证信息」中复制
APP ID与Access Token
3. 在说点啥中配置
- 打开
设置 → 语音识别设置 - 选择 Volcengine(火山引擎)
- 将
APP ID填入X-Api-App-Key - 将
Access Token填入X-Api-Access-Key - 如需流式识别,开启「使用流式识别(WebSocket)」

提示
若创建应用时已同时开通流式与录音文件识别,二者使用同一套密钥,无需重复获取。
硅基流动(SiliconFlow)
硅基流动提供内置免费 ASR(无需 Key)以及可选的付费模型。
快速使用(无需 API Key)
- 在
设置 → 语音识别设置中选择 SiliconFlow - 保持「免费 ASR」相关开关为开启
- 在可用的免费模型(如
FunAudioLLM/SenseVoiceSmall、TeleAI/TeleSpeechASR)之间切换即可
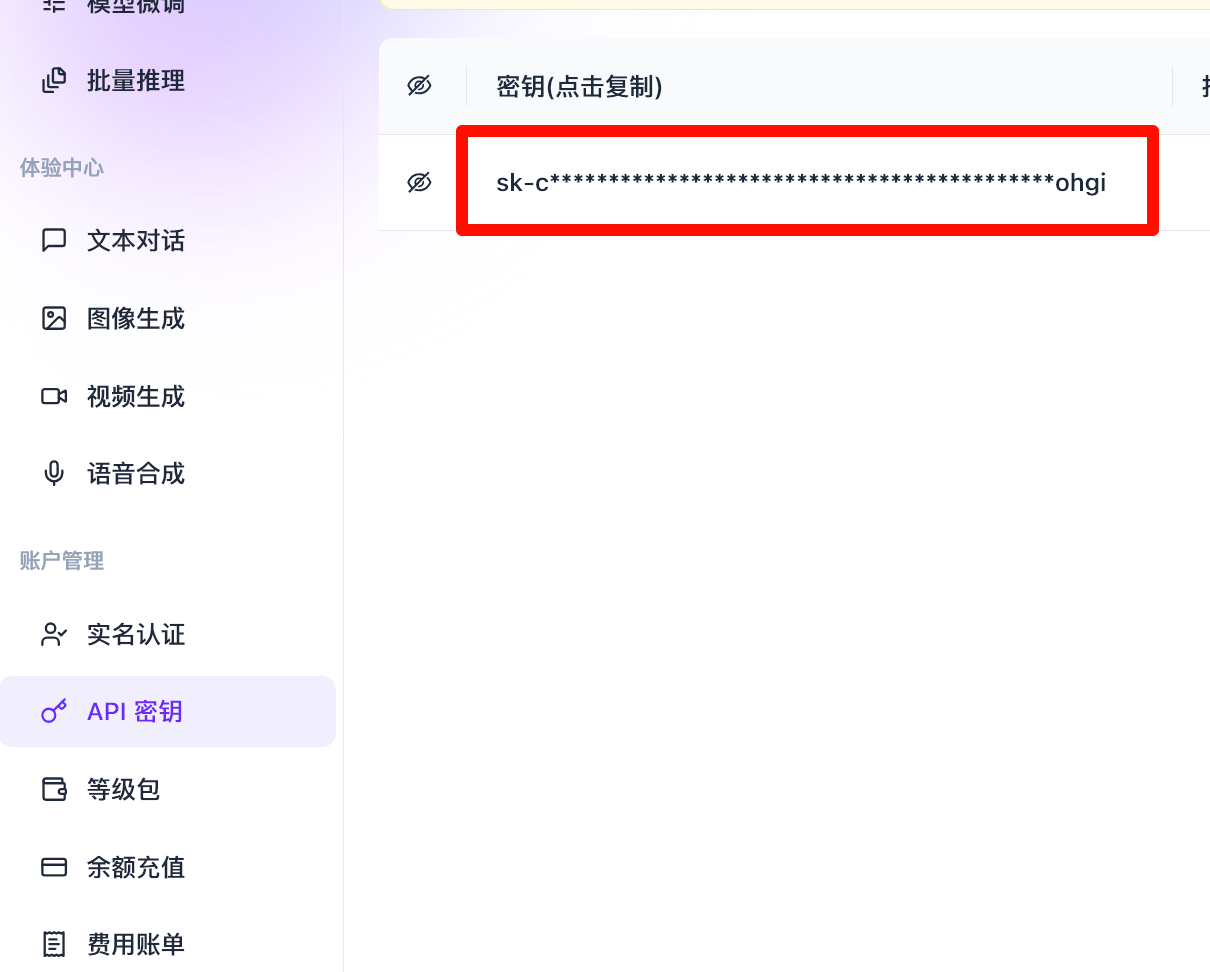
使用自有 API Key(可选)
- 注册并登录:硅基流动官网
- 在控制台进入「API 密钥」,创建并复制 Key
- 粘贴到说点啥对应的 SiliconFlow 配置项中
阿里云百炼(DashScope / Qwen)
识别精度不错、性价比高;支持非流式,流式部分支持。
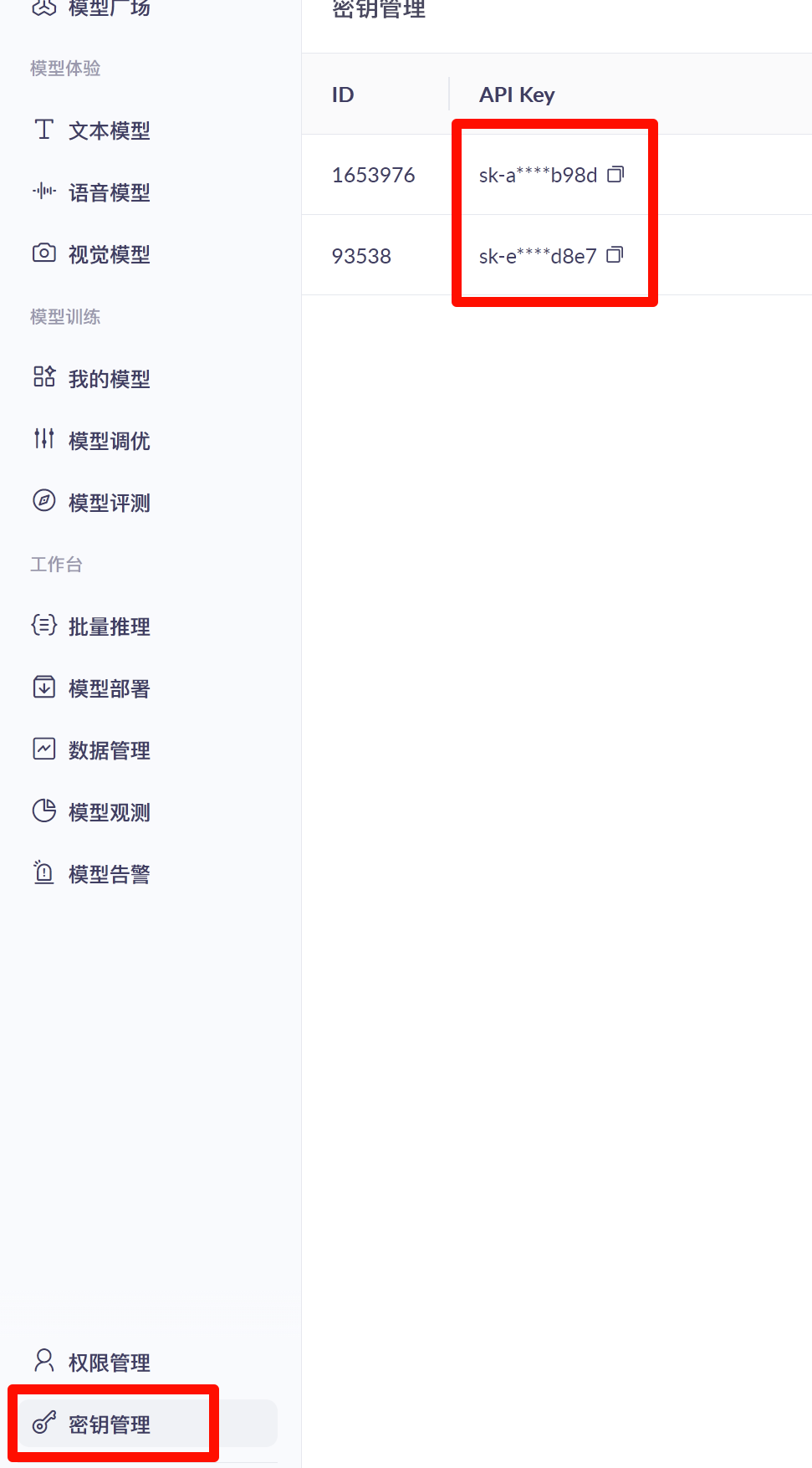
1. 创建并复制 API Key
- 进入控制台 API Key 页面:阿里云百炼控制台
- 创建并复制 API Key
2. 在说点啥中配置
- 打开
设置 → 语音识别设置,选择 DashScope(阿里云百炼) - 填入 API Key 并保存
- 根据需要选择模型:
Qwen3-ASR-Flash、Fun-ASR-Flash、Qwen3.5-Omni-Flash、Qwen3.5-Omni-Plus或流式模型
模型选择
Qwen3.5-Omni 适合非流式多模态转写;Fun-ASR-Flash 也是非流式模型,但不支持识别语言和自定义提示词设置。流式识别默认使用 qwen3-asr-flash-realtime-2026-02-10,也可切换到 fun-asr-realtime。
Cohere
Cohere Transcribe 在说点啥中以非流式文件识别方式使用。
- 登录 Cohere Dashboard,创建并复制 Trial API Key
- 打开
设置 → 语音识别设置,选择 Cohere - 填入
Cohere API Key - 选择模型:
cohere-transcribe-03-2026:通用多语言模型cohere-transcribe-arabic-07-2026:阿拉伯语 / 英语模型
- 选择与语音匹配的识别语言;若填写自定义模型 ID,请同时确认该模型接受所选语言代码
免费限制
Cohere Trial API Key 限制为 5 RPM(每分钟请求数)。
语言选择
通用模型支持中文、英语、阿拉伯语、日语、韩语及多种欧洲语言;阿拉伯语模型仅提供阿拉伯语和英语选项。
Soniox
Soniox 支持流式与非流式;流式稳定性较好。
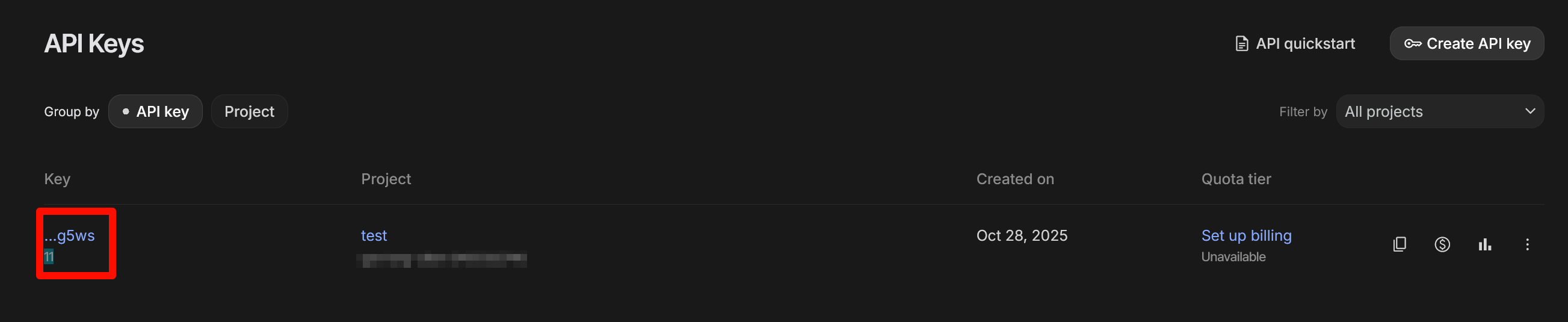
获取 API Key
- 登录控制台:Soniox Console
- 在项目侧边栏进入
API keys - 创建并复制 API KEY
识别模式
在 Soniox 设置中可通过滑块调整「端点检测灵敏度」:
- 低延迟:更快的端点检测,适合实时输入
- 默认:平衡延迟与准确率
- 高精度:更敏感的端点检测,适合对准确率更敏感的场景
Gemini
Gemini 适合小用量体验,通常以文件识别为主。
- 进入 API Keys 页面:Google AI Studio
- 创建并复制 Key
- 填入说点啥对应的 Gemini 配置项
ElevenLabs
ElevenLabs 的 scribe_v1 仅支持非流式,scribe_v2 仅支持流式。
获取 API Key
- 进入 API Keys 页面:ElevenLabs API Keys
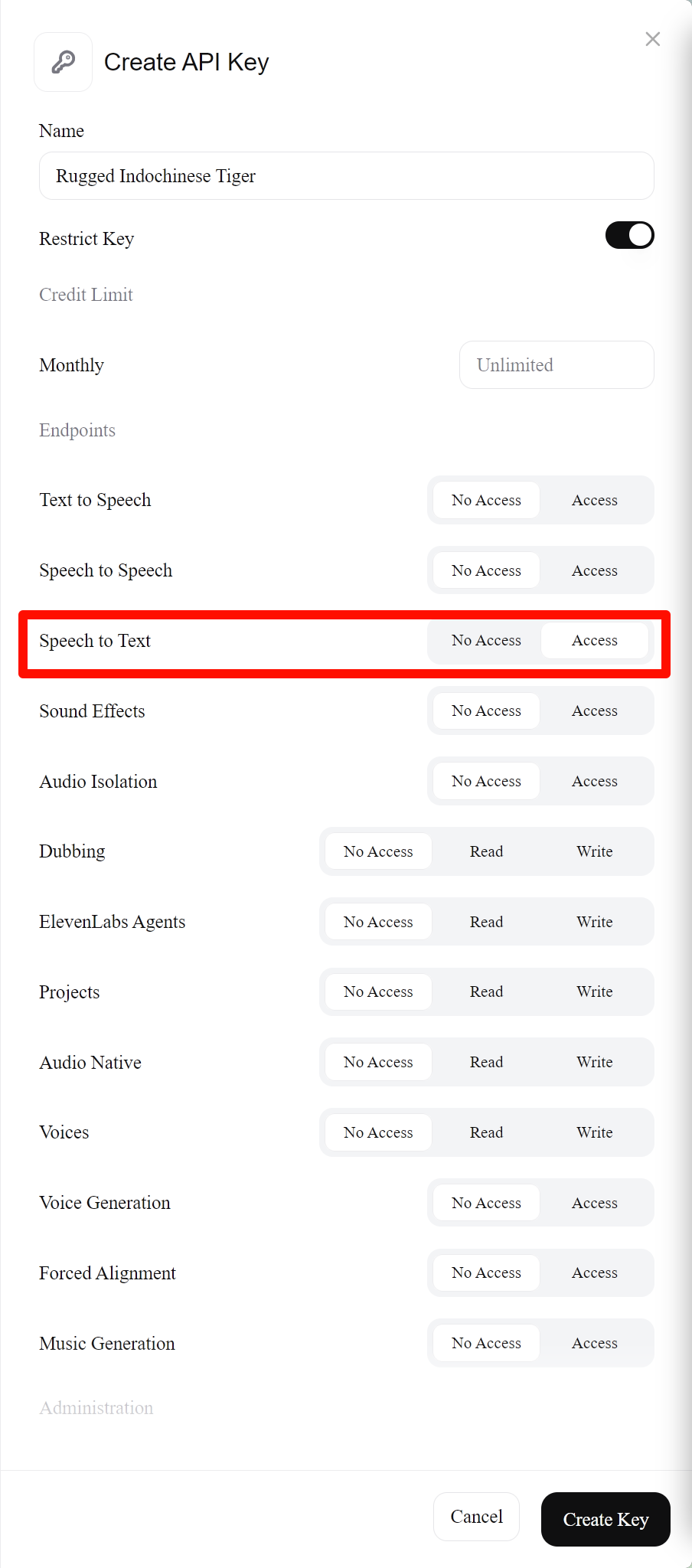
- 点击 Create Key
- 为 Key 开启
Speech to Text权限
OpenAI(兼容接口)
OpenAI 渠道支持使用 OpenAI 格式的 ASR 端点(也可填写兼容 OpenAI Audio Transcriptions、Chat Completions 或 Realtime 的第三方端点)。
- 在
设置 → 语音识别设置选择 OpenAI - 通过「添加渠道」建立一个或多个 OpenAI ASR 配置,用于区分官方接口、代理接口或不同模型
- 填写:
ASR 端点(如https://api.openai.com/v1/audio/transcriptions、https://api.openai.com/v1/chat/completions或兼容端点)API Key(Bearer)模型名称(如gpt-4o-mini-transcribe/whisper-1)
- 如果端点是多模态 Chat Completions 接口,开启「使用 Completions 接口」,并按需填写自定义 Prompt
- 如果端点支持 Realtime API,可开启「启用流式识别(Realtime)」以边说边显示结果
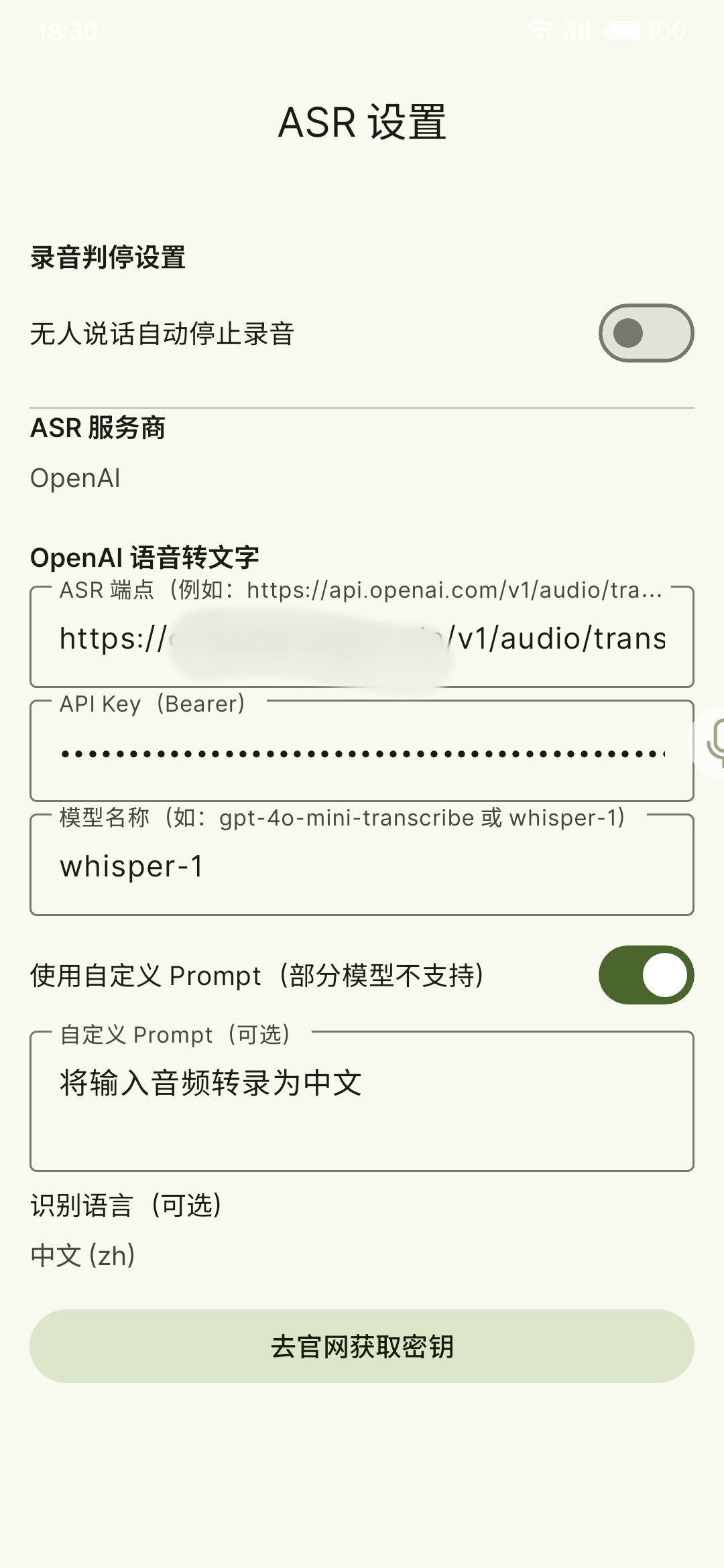
选择哪种 OpenAI 接口
audio/transcriptions 适合标准转写模型;chat/completions 适合支持音频输入的多模态模型;Realtime 适合需要边说边出字的流式体验。需要确认你的 OpenAI 渠道支持哪种调用方式。
自定义兼容端点
使用自定义兼容的 audio/transcriptions 端点时,说点啥会上传 WAV 音频以提高兼容性;此时「上传音频前压缩」不会对该 OpenAI 自定义转写端点生效。
OpenRouter
OpenRouter 渠道用于通过 OpenRouter 调用兼容的 ASR / 多模态转写模型,目前以非流式方式使用。
- 进入 OpenRouter 控制台创建 API Key:OpenRouter Keys
- 在
设置 → 语音识别设置中选择 OpenRouter - 填写:
ASR Endpoint(通常保持默认或填写兼容的/audio/transcriptions端点)OpenRouter API Key模型(例如qwen/qwen3-asr-flash-2026-02-10)
- 保存后可先到
设置首页 → 录音测试验证是否可用
MiMo(小米)
MiMo 渠道支持 mimo-v2.5-asr 与 mimo-v2.5 音频理解模型,适合希望尝试小米 MiMo 转写效果的用户。
- 准备 MiMo API Key
- 在
设置 → 语音识别设置中选择 MiMo - 选择请求端点:
- Token Plan(中国大陆 / 新加坡 / 欧洲)
- 按量付费
- 自定义端点
- 填写当前端点对应的 MiMo API Key。不同端点预设会分别保存 Key,切换端点时请确认当前槽位已配置
- 选择模型、识别语言(自动 / 中文 / 英文)
- 使用
mimo-v2.5音频理解模型时,可填写 System Prompt;如不需要推理过程,可开启「禁用推理」
StepAudio
StepAudio 是阶跃星辰提供的在线 ASR 服务,目前在说点啥中以非流式方式使用。
- 进入阶跃星辰开放平台并创建 API Key:StepFun 控制台
- 在
设置 → 语音识别设置中选择 StepAudio - 选择请求端点:
- 按量付费
- Coding Plan
- 自定义
- 填入当前端点对应的
StepFun API Key。不同端点预设会分别保存 Key,切换端点后请重新确认 - 选择
stepaudio-2.5-asr模型、识别语言(中文 / 英文 / 自动)并按需开启 ITN
智谱 GLM
智谱 GLM 渠道简单易用、价格较低,通常为非流式。
- 进入控制台获取 API Key:智谱 BigModel 控制台
- 将 Key 填入说点啥对应的智谱配置项
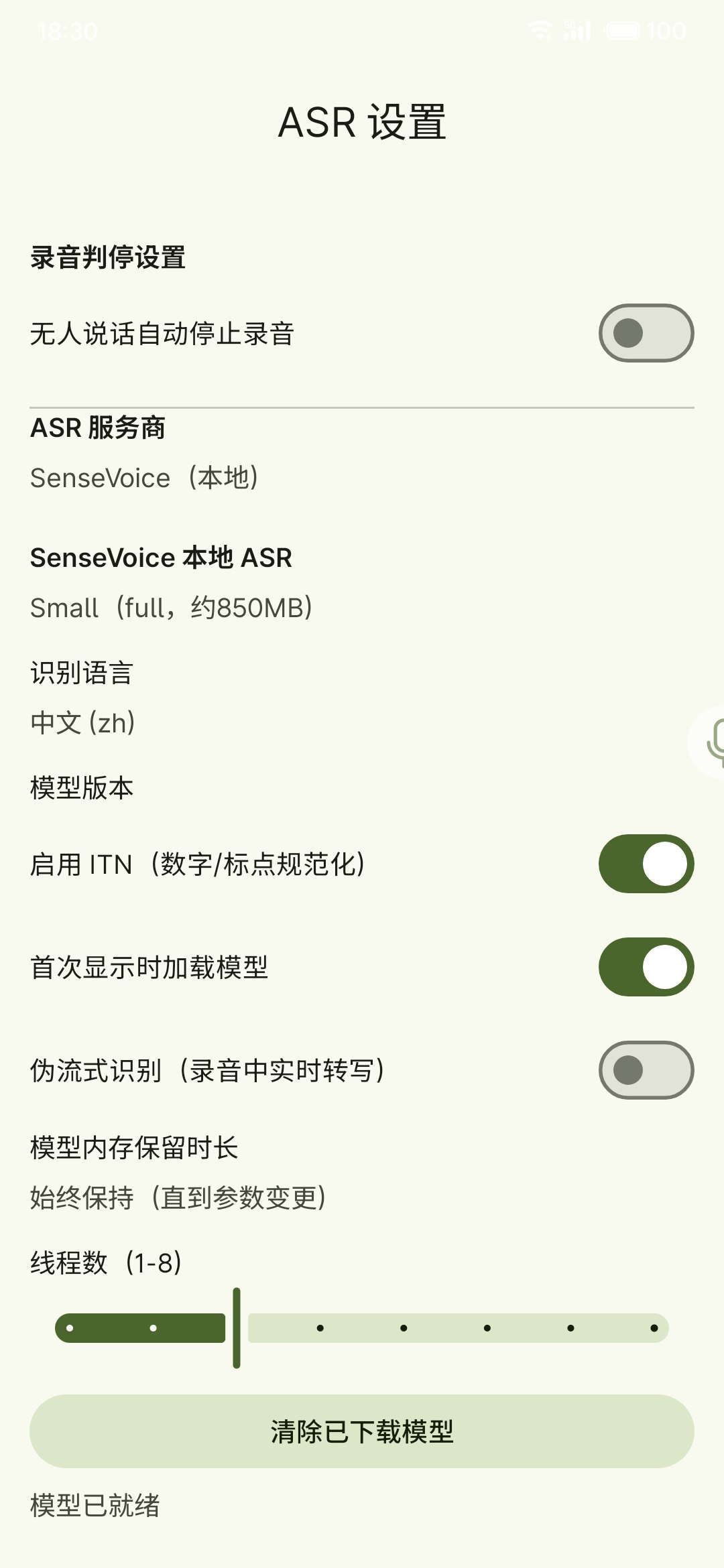
本地模型配置指南
本地模型适合隐私优先与离线使用。不同模型在速度、效果、是否流式上各有取舍。
模型选择建议
- SenseVoice:非流式;速度快、均衡;支持语言设置
- FunASR Nano:非流式;支持语言选择、原生 ITN,并提供 MLT Nano 多语言变体
- Qwen3-ASR:非流式;本地 0.6B 模型,中文效果较好
- Parakeet:非流式;V3 适合多种欧洲语言,V2 适合英语
- FireRedASR V2:非流式 / 伪流式;替代旧版 TeleSpeech,支持中英本地识别
- X-ASR:本地流式;中英 480ms 模型,支持线程数、模型卸载策略与可选 ITN
在应用内下载(推荐)
- 选择本地模型供应商(如 SenseVoice / X-ASR)
- 在模型管理页选择版本并点击下载
- 如已授予通知权限,可在通知栏查看下载与解压进度
下载被取消或网络中断时,未完成的下载任务会暂存在本机;再次下载同一模型时会尝试从断点继续。缓存最长保留 7 天,总占用上限约 2 GB,超过限制时会优先清理较旧文件。若下载源不支持断点续传,应用会自动重新下载完整文件。
通过本地文件导入(可选)
如果你偏好通过本地文件添加模型,可先下载 ZIP,再在模型管理页选择“从本地导入”。
模型直链
以下为 BiBi-Keyboard 模型 ZIP 直链;如遇到 404/下载慢,请前往 模型库(Releases: models) 或使用 GitHub 镜像站下载。
SenseVoice(非流)
- small-int8(约 153MB):sherpa-onnx-sense-voice-zh-en-ja-ko-yue-int8-2024-07-17.zip
- small-fp32(约 980MB):sherpa-onnx-sense-voice-zh-en-ja-ko-yue-2024-07-17.zip
X-ASR(流式)
- 中英 480ms(约 530MB):sherpa-onnx-streaming-x-asr-480ms-zh-en.zip
FireRedASR V2(非流 / 伪流)
- Zh + En CTC int8(约 740MB):sherpa-onnx-fire-red-asr2-ctc-zh_en-int8-2026-02-25.zip
FunASR Nano(非流)
- int8(约 690MB):sherpa-onnx-funasr-nano-int8-2025-12-30.zip
- MLT Nano int8(约 690MB):sherpa-onnx-funasr-mlt-nano-int8-2026-03-21.zip
Qwen3-ASR(非流)
- 0.6B int8(约 806MB):sherpa-onnx-qwen3-asr-0.6B-int8-2026-03-25.zip
Parakeet(非流)
- 0.6B V3 int8(约 456MB):sherpa-onnx-nemo-parakeet-tdt-0.6b-v3-int8.zip
- 0.6B V2 int8(约 451MB):sherpa-onnx-nemo-parakeet-tdt-0.6b-v2-int8.zip